
It was the summer of 2010, and I had run the exercise of my stock market algorithms on Google sentiment data, colors, Fortune 500 brands, and emotions. I was ecstatic because the algorithm I had created worked brilliantly across alternative data. The algorithm was agnostic to data and did not care whether it was fed stock market data or data from another domain. This something else indicated a data universality, a context that was common to all data sets.
This non-financial capability illustrated robustness. The applications were endless. For a start, I imagined creating a newer business line, which was better than Google Trends. I started visualizing this overlay on the current internet search engines, which could give quantitative insights and analytics on all kinds of chronological data. After all “page rank” was a simple algorithm that changed the world, what I had was something simple, but designed to predict, so it naturally, I believed, should have a lot of global potential.
Years passed, and I had to build the financial technology to deliver these algorithms globally to anyone who needed them. In 2012, I met Vlad Ioane, who spoke at a conference in Bucharest. He was the COO of a company doing cutting-edge work in sentiment analytics with a company named UberVu. So, while my ideal client profile was investment managers, I wanted to apply the algorithms in a real-time sentiment analytics business. It would diversify the revenue line and also give access to a market larger than the financial market.
Vlad was kind enough to give me a meeting and was open to trying out the algorithm on sentiment data. I showed him a study called, “The Fortune Index” where a portfolio of sentiment data was benchmarked against equal-weighted Google data. The portfolio assumed the sentiment of Fortune 500 brands as stock prices. Though the portfolio’s outperformance against the benchmark was notional, it was a sign of an intelligence layer on Google sentiment data. Vlad was impressed and wanted to go a step further, wanting to try it on UberVu’s sentiment data. He shared with me the sentiment data of various brands and asked me to extend the exercise to a tangible use case for him. I came back with another study called the “UberVu Sentiment” where we could add quantitative character to relative study of brands like Johnny Walker and Jack Daniel. By the end of the study, we could explain which brand was expected to rise in positive sentiment and which one was forecasted to see a drop-in sentiment value. When I showed him the study, he said, “This is brilliant but predictive analytics (on sentiment data) are ahead of their time”. This was in 2013. I had spent 12 months building a non-financial showcase for a top sentiment analytics shop just to realize that I was living in the future. A few months later, UberVu was sold to Hootsuite, Canada’s top startup in Sentiment Analytics. The company today has nearly 20 million customers, work across 175 countries and they still don’t have those predictive analytics.
The problem with peeking into the future is the difficulty to close the window once it’s open. Now the world has more data. Generative AI is processing unstructured data at a breakneck speed, incorporating AI into day-to-day applications. The game has moved away from data curation to automated solutions, from standardization to individualization, from search to summary. Today is less about data science and more about AI-powered data assets (services). The world is exponentially moving to alternative assets which are finding their way to the investing communities. The further we move ahead with AI, the more information we create. The more information we create, the more we reach back to where we started. Information is a vicious loop and if we need to think fundamentally differently, we have to acquire the escape velocity to move from the informational age to the conceptual age, the age of intelligence. This is why we set up AlphaBlock back in 2018.
“As intelligence moves from arbitrary and erratic patterns of human discretionary knowledge-building toward a more systematic and organic AI, there is a need for a new market mechanism to validate, distribute, and reward intelligent processes. Such an intelligent market is built on a systematic, scientific, replicable (SSR) process that is objective, accountable and can be validated and used by the community. This general intelligence or “alpha” should be content-agnostic and context-focused - an alpha process reconfiguring the block of the blockchain into ‘AlphaBlock’, an intelligent market mechanism. Alpha prediction has conventionally been associated with domain-specific content and is known to be predictive systems that are non-replicable and are mostly non-scientific. The author defines a General AI predictive process that can be fused into the blockchain block, transforming the blockchain into a multi-purpose predictive tool which self-builds, self-protects, and self-validates. AlphaBlock becomes the essence of everything linked with data predictability, evolving into an intelligence layer on the blockchain and the web. It is a predictive ecosystem which blurs the distinction between financial and non-financial data - ultimately removing barriers between financial and services markets. The blockchain can achieve this evolved state and become an intelligent market state if it crosses three key hurdles: First, it securitizes blockchain assets and creates new alternative assets and asset classes. Second, it resolves the incapability of conventional finance to understand risk effectively and enhances return per unit of risk (outperform the market) using a General AI process. Third, it must offer a better mechanism to address currency risk than what is offered by the existing fiat currencies and cryptocurrencies.”
As time passed, I continued nibbling at the problem and continued to experiment with different data sets.
An excerpt from “Researching Google Search”, 2011
“Everything from the number of searches to what we search is connected with time, and any predictive cycle tool that can measure and predict emotion and help societal mood researchers understand where a society is headed and where it was when hope was rising and where will it go and when hope will fall.
We decided to test our algorithms on Google search data connected with emotions. Emotions are important for Socioeconomics. We ranked these group of emotions and Indexed them for a trend, a Jiseki cycle, to not only see which emotion came on the top and bottom but also to understand whether the society was getting happier or not.
So, if we could establish that fear was increasing or decreasing in society, we could feel its pulse. This was a powerful tool. We took the five-year data of all possible emotions from anger to anxiety, excitement to fear and hope to surprise. We ranked these for a quarter. Hope and surprise were at the top, while apathy and anxiety were at the bottom.
The plot suggests falling boredom, hope and hostility cycles on one side, and rising excitement, bottoming jealousy, strengthening loneliness and stagnating love on the other. Now, we one could raise more related queries around this data. How good was Google search sample of emotions? Whether the internet user was happy when he searched for happiness? We could also ask specific questions regarding why the Jiseki cycle of search on loneliness was strengthening while that of the number of searches regarding love was stagnating?”
I was envisioning today’s generative AI chat on sentiment of emotions back in 2011.
An excerpt from “The Fortune Index”, 2012
"Data models should work across regions, across assets and across domains. This means “Data Universality”. If natural phenomenon exhibited universal patterns like geometry, outliers, mean reversion, fat tails etc. then the data these natural phenomena generate should also express a similar behavior. However, we still consider data as religion, (something that can’t exhibit fusion). The stock market data is useful for the financial analyst, while the subatomic data is useful for physicists, the social network data is for marketers.
We see similar trends in all datasets, but we don’t mix and match sub-atomic, social and stock market data. Why? Because it would be kind of blasphemy if Higgs particle data would have any similarity to stock market data. The objective thought would be that stock market data can’t be reconciled with subatomic data as the respective elements vibrate at a different frequency. Yes, that’s true, but social data has a workable frequency with stock markets. This is the reason twitter forecasting is in vogue, and companies are relying on the sentiment today to understand consumers and market trends. And then there are sentiment funds, using twitter data to trade.
What’s the challenge in fusion? Charles Handy called it paraphernalia. Calling a seamstress, a designer does not change her real role. In the process of finding and worshiping big data tools, we live in an illusion of progress because we don’t acknowledge the elephant in the room, it’s the same elephant but we call it something else. We chose to ignore that the answer to tomorrow’s problems is not in a discipline, but between disciplines.
We took Google search data for Fortune 500 companies, various emotions and ran our data algorithms on the same. Just like gold, oil, dollar we could create cycles of growth and decay for simple web data. We could predict which Fortune 500 company brands would be searched more and which will see decay in the search. We equal weighted the selected brands and tied their value to correct prediction i.e. increasing brand sentiment. In a short period of 24 months, our “Fortune Index” moved up from 100 points to 120 while an equal weighted Google search data of Fortune 500 fell by a negative 10%. Our Index outperformed its respective universe by 30% over 24 months.
The age of big data accompanies numerous data types like web date, social data, and consumer data. Hence it has become essential to lay down a framework for data universality. This means commonality of behavior, commonality of patterns and data character. Such guidelines could make data visualization, transformation and interpretation easier. The natural universalities leading to data universality can harmonize big data classification and improve the predictive model."

Sentiment data as a proxy for stock prices

Fortune Index (Red) benchmarked against an equal weighted Google Sentiment Index (Right). The Fortune Index value superseded the benchmark value.

Jiseki cycles on sentiment data
An excerpt from “UberVu Sentiment”, 2012
"We took the UberVu sentiment data and combined it as a part of a homogeneous group of sentiment data to predict which sentiment data was growing, which was decaying, which had hit an extreme low and would revert and start growing again. Apart from this we could overlay the sentiment data with a signal system using our dynamic ranking systems which express themselves as Jiseki Performance cycles. What did we find? Heineken, Facebook, Samsung, Apple and Microsoft were the top ranked components of the group. While Sprint, Smirnoff, Bacardi, Belvedere and U.S. Cellular were the bottom ranked components of the group. Speaking about universal laws, growth and decay are seasonal and hence despite any momentum that a winner or loser may have, the top performer invariably slows down and vice versa.
For advertisers watching this sentiment data, relative growth in JD vs. JW would mean that ad budgets have more efficiency for JD which is relatively set to outgrow JW and rest of the brands in the group. Advertising efficiency is an understudied subject and sentiment Jiseki (growth and decay) is a first step in understanding the same. For advertisers watching this sentiment data, relative growth in JD vs. JW would mean that ad budgets have more efficiency for JD which is relatively set to outgrow JW and rest of the brands in the group."

Jack Daniels vs. Johnie Walker Sentiment Jiseki

Sentiment metrics

Group behaviour
Universal Indexing
While I was testing the algorithm on non-financial data back from 2010 till 2013, I knew that the predominant Indexing method with market capitalized weighting was poor and needed to be redesigned but I did not know the extent of inefficiency of the method and how it was statistically flawed. The reason it stood unchallenged was because Science had not progressed enough to understand that the Index was posing a mathematical puzzle, solving which was essential for the advancement of Science. It took me time to appreciate that the testing of the methodology across diverse data sets was a critical step to not only evolve the method but also appreciate the role of universal indexing to transcend from the world of data to the world of intelligence. The current shift towards chat machines that summarize information has made it easier to apply such meta layers on data, something which could not have been done earlier.
Universal Indexing is critical for the Intelligence society. If an Index only works on a specific region, or specific asset for a specific time, it is not universal and is not an Index. I explained in “The S&P Myth”, “The Beta Maths” and “The Snowball Effect” how current market capitalized weighted Indexes are flawed, not scientific, perpetuate the winner bias, and have reached mainstream because of a calculation convenience. Universal Indexing operates in a world that is factor agnostic and assumes that factor prediction is an impossibility. This is why Universal Indexing has to rely on statistical innovation which understands complexity and chaotic systems. Universal Indexing predicts group behavior across domains, starting points, and regimes. And hence becomes an essential test to overcome the challenge of data mining, backtesting, and optimization. Universal Indexing was impossible without the features of Data Universality.
An excerpt from, “The Data Universality”, 2013
"Databases should talk to themselves and if natural systems express universal laws like patterns, divergences, seasonality, and constants then the data generated or derived from these natural systems should also express this universality. And if the data also express this universality then the question to be asked here is whether the universality character lies in something common to data rather than to a natural system.
This is what we refer to as data universality. Universality can be defined as the aspects of a system’s behavior which are independent of the behavior of its components. And even systems whose elements differ widely may nevertheless have common emergent features. There are common universal behavior in data sets irrespective of its organic source of generation or derivation. Assuming data universality is a science. What does it change? The elephant blows away the blindfolds and finally, psychologists, technicians, fundamentalists, statisticians, mathematicians, scientists, etc. talk the same language. An economist or physicist never thought their paths could meet, till one physicist jumped the ship and created Econophysics.
Another paper written in 2004 by “Universality in multi-agent systems”, Parunak, Brueckner, Savit on Universality talks about the universal behavior of natural systems. The three stages consist of randomness, order, and herding. The universality paper suggests that the reason agents don’t optimize their decision making is owing to time constraints.
While the world spends resources and time to make sense of information, it passes through stages of relevance and irrelevance. For more than half a century researchers have debated on intelligent systems that can make sense of this information. Nature is an example of an intelligent system, which selects relevant information and ignores the noise. Systems have common properties that are independent of their specific content. Data Universality is a commonality that governs a data set irrespective of its source of generation or derivation, an intelligence that defines the architecture of complexity, allowing the user to understand, anticipate and relate data intra-domain or inter-domains. Data Universality redefines anticipation (predictability) at a system level and connects industries and domain knowledge as never before. This allows the user to identify the relevant information, simplify the complex, understand the mechanism that generates uncertainty and hence manage the risk better."

Unique features of Data Universality

Data Universality is agnostic to domains
Data Enrichment
Like the dual nature of a particle enriches its character, a data variable is a complex entity that needs enrichment to identify its true form. A data variable has many characters, content is just one, and context is another, which changes temporally, shining like the spectral analysis that led Neil Bohr to create quantum theory.
Somewhere, our journey to an intelligent world, when we know more about complexity, and more about prediction is connected to our ability to enrich our datasets. And we can do that by asking these questions. Does our data have a dual character? Does it have both context and content? If it has context, what’s that context telling us? Now as simple as these questions may sound, understanding context is like seeing a map. Because every data variable has a legacy, it did not come from nothing, it has a history. We don’t have the tools today, to screen a data point and look at its contextual spectrum. If we had a data map and could see where the data has come from and where it was likely to go, we have catapulted ourselves into the intelligence age.
I always think of data as a guitar string. A group of strings vibrate together and make music but only because every single string strand is capable to vibrate on its own. We can’t have smart intelligent databases if we don’t have enriched data. The data point is where it all begins, a singular strand that is aware of itself, even if we can’t see it.
In this data-enriched world, we won’t need a fraction of data to train, classify, and predict. We could use a singular data point (or even proxy data) to know everything about its past and its potential future. In this world, domain-specific will be replaced by domain-agnostic. Content would be replaced by contextual mechanisms. Society would understand a lot more than causal explanations. The effect would create a string of causes to keep the data aligned on its most likely path. The whole idea of predictability would look like Asimov’s psychohistory. The more we move into this data-enriched future, the more the world we live in today would look like Stone Age. That’s the nature of Science, the more it progresses, the more it becomes magical.
In this data-enriched world, databases would understand each other, talk to each other, assimilate knowledge, and hence build more conscious systems. All this starts from understanding that what we search today is not an isolated event, but something connected on a historical calendar, a clock. And if we see that context, predictions that can measure emotion in the short term can also help comprehend where society is headed and where it was when hope was rising and where will it go when hope shall fall.
Data enrichment is not science fiction. Once we enhance the Science, we will see the data not only with character but with architecture.
An excerpt from, “Architecture of Data”, 2016
"Financial markets have moved from regional to global, from one asset to Intermarkets. This has created a critical mass of data where understanding group behavior has assumed more importance than the need to understand a component of the group, a fruit from the basket. The trade-off is between the micro and the big picture, and between human and system ability to interpret data and information. The idea is not about one vs. the other but the coexistence of the group with the component.
Though Boulding had talked about the oscillation of information from relevance to irrelevance, we discounted him for more than 50 years. Markets had to experience itself that causal explanation is not Science. Today’s relevant cause is likely to become irrelevant tomorrow. More information is not always better and can increase complexity.
It has taken the society a while to understand that the wisdom of crowds worked because the madness of crowds pulled the society to the extremes, which invariably had to correct (revert). How can a system work if it does not have an internal unbalancing and balancing mechanism? The whole meaning of activity comes from inefficiency. We need irrational exuberance for sanity to return. We need to have greed for fear. The relevance of information is rooted in its irrelevance.
A circular argument rots finance. Modern finance is an extension of economics. Understanding behavior needs more than economics, it needs pure sciences to understand the mechanism that creates and diffuses bubbles. To assume that human beings are emotionally challenged because they cannot add and subtract is a subjective thought process. Emotions do not create the system; they are driven by the system. The process that drives nature also drives market. This is why what started as a Galtonian height experiment ended up becoming a law. Information is an assumption for modern finance. The Efficient Market Hypothesis uses information to back its case for efficiency.
According to Herbert Simon, the architecture of complexity was intrinsically simple and hierarchal. The structure was more important than the content. There was a commonality across various types of natural systems including market systems. The whole was more than the sum, suggesting complexity generated by a definable structure."
“It’s a mistake to think of economics as a Science with a capital S. There is no economic theory of everything and attempts to construct one seems to merge toward a theory of nothing”
Robert Solow
“I can see no other escape from this dilemma (lest our true who aim be lost forever) than that some of us should venture to embark on a synthesis of facts and theories, albeit with second-hand and incomplete knowledge of some of them - and at the risk of making fools of ourselves. So much for my apology.”
Erwin Schrodinger
"If data had nature in it and if data indeed became the code (Neuman) or we the new society was the Borge’s map, the question about the architecture of data (AOD) became paramount. The structure will be more important than the inferences that come out. The challenge would still to understand the behavior of the flock of birds, the structure in the chaos. A single system with connected components. Self-describing, self-interpreting, intelligent and not artificial.
The AOD just likes its stacked counterpart is about, collaboration, strategic thinking, ubiquitous connectivity, lower computing costs, seeking invisible patterns, the single universally accessible document, looking at data as infrastructure, self-correcting inferences, data sharing etc. AOD was built on the assumption that similar challenges and strategies applied for many businesses and that the world needed predictive insights not just for few days for a few years ahead. Domains were not only interconnected but interdependent.
The Web 2.0 is going through its data science revolution. It has community data and it starts to understand user behavior through user choices. We have crossed the stage from domain community to domain data. The AOD will be about the interaction between data from various domains. The standardization, integration, and interpretation across domains of data will be a part of the Web 3.0. This leads to data universality, when data commonalities are explored for individual (component) and domain (group) benefit, for inferences and to anticipate immediate and intermediate evolution. We will be the part of a thriving organism then. AOD could potentially drive Web 4.0, the ultra-smart agent which caters to various user needs. Web 4.0 won’t be artificial but simply intelligent. If this proposed scenario holds, FinTech will morph into the architecture like many other components. The structure will become more important than the content."

Architecture of data
An excerpt from, “Date before ML”, 2021
"Intelligence is about solving a chaotic problem; you can see the manifold (the butterfly wings) but never exactly know when and which wing will the form flip too. Data is the bottleneck and the gold mine when it comes to building such systems.
ML could be understood as something supervised or unsupervised, leading to a classification by error reduction.

Plain vanilla view of ML
An ML system based on a data architecture that mirrors or has semblance to the data generating mechanism improves performance. Because it asks, where is the data coming from? How should the data architecture be? Will the dataset lend itself well to the chosen ML process?
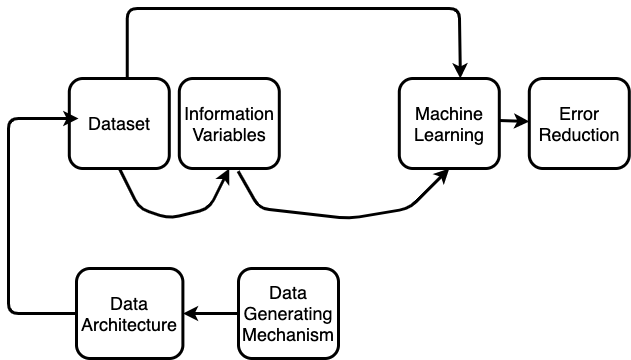
Data Generating Mechanism View of ML
However, a data generating mechanism and a good architecture which assumes stability and linearity in information could stay biased and deliver erroneous results. Specifying a linear model and expecting it to understand causality has lead modern finance to a set of conflicting theories over the last 100 years. So to expect such an approach to solve the challenges of the non-financial domain is naive thinking.

Causal Complex View of ML
And because causality eventually leads to chaos, a robust ML system should specify a model assuming a varying and dynamic degree of influence between a set of causes, expect some causes to fail and new causes to emerge and succeed. Such a system makes no assumption about information validity and embraces both error reduction and amplification as an output.
Data heavy or data light is not a characteristics of the ML process, but of the data architecture. One can use a good data architecture to sample the data well for the ML process. A well-designed architecture can drive the ML process with a fraction (e.g. less than 10%) of the data, which is refreshed periodically. Therefore, it’s essential to ask, how much of my database do I really need for my ML process to run optimally? The more carefully we use data for training, the less biases we introduce in our ML processes and the less electricity we burn, a desired objective in a computation heavy world.
If we want to build ML systems to simulate real world problems, we have to train them on datasets that evolve from an understanding of data generating mechanisms, appropriate data architectures, and causal complexity which bases itself on the assumption that there is a certain probability of failure and success of a cause to affect."
Intelligence Assets
Universal Indexing will become a prerequisite for Investing in the future. If an Index fund won’t show consistent outperformance, it won’t scale in assets. This would be even true for alternative assets, which will have to be universally Indexed. Eventually, these alternative assets will become significantly larger than conventional assets like equity and bonds, ushering in a future that will not be about 10,000 liquid assets but trillions of intelligence assets extracting intelligence from data in some form, persistently. In the first phase of web 4.0, these assets will get priced, traded, and exchanged for value, but in the later part, the idea of valuation, control, liquidity, and money will transform into some other meta version of intelligence.
Conclusion
Data is the last thing we think about in the world of AI. It’s something that is generated, collected, and stored. It’s not something that has universality, can be enriched, and can transform our AI tools. The lack of Indexing tools complicates the data problem further. Indexing is not a science and has perpetuated errors for more than a century into our life through our data. Every day we generate more data but the idea of indexing this data is still unclear. If you can’t Index the data, you can’t extract intelligence out of it and if you can’t extract intelligence, one wonders about the real utility of AI. Is it to create more information or is it about creating next-generation tools that can create insights and predict? Society needs Universal Indexing to extract intelligence from any data because we need tools to compress our data, reduce computation costs and transform information into intelligence. We need to start thinking conceptually and contextually to move to an intelligent society. Otherwise, we risk drowning in our data.
Data universality and enrichment are the future of AI because AI without enriched data is a path of immense resistance. It’s an inefficient way to build AI systems. The failure of today’s predictive systems, be it investment funds, sentiment funds, or behavioral funds are based on non-scientific processes which have a limited life and application. The intelligent web (4.0) will rely on the new data foundations to transform our day-to-day life, where our AI systems will not hallucinate but will understand and comprehend what they are speaking and what is being asked. They will be like Vox from the 2002 film Time Machine, coherent, helpful, and ready to take us to a world where predictions would be simply a commodity.
You can access our Universal Indexing Methodology through AlphaBlock's Sandbox on Github. We encourage you to reach out to us, if you work with non-financial chronological data and would like to apply our Indexing process to your data to derive predictions, insights and analytics.