The rich do not always get richer. Explaining this probabilistically resolves a 100-year-old puzzle, opening up opportunities for smart beta portfolios, an architecture of complexity and eventually an architecture of data that could become Web 4.0.
Group vs. Component
Financial markets have moved from regional to global, from one asset to Intermarkets [1]. This has created a critical mass of data where understanding group behavior has assumed more importance than the need to understand a component of the group, a fruit from the basket [2]. The trade-off is between the micro and the big picture, and between human and system ability to interpret data and information. The idea below is not about whether one is better than other, because both need to coexist. The idea is that the markets have attained critical mass for us to ignore the meaning and behavior of a group. Just like markets, nature is ruthless and is an incessant battle of systems. Currently it is the no-rule based systems [3] or component based selection methods that are under attack from the rule-based baskets. Today, it is not just finance but other industries that are moving from specialization to integration. We are in interdisciplinary times. This is why ignoring the influence of group on its components is risky.
Information relevance and irrelevance
The inter and intra group dynamics generates information. There are various ways to interpret this information. Today selection systems (fundamental, quantitative or behavioral etc.) compete for the same assets. Fundamental systems took a beating with successive crisis [4] as psychology and quantitative systems took a lead. Over the last decade, behavioral systems have been criticized for underperformance. The systems have failed to offer a better framework for understanding markets [5].
Though Boulding [6] had talked about the oscillation of information from relevance to irrelevance, we discounted him for more than 50 years. Markets had to experience itself that cause and effect is a weak science. The relevant cause might become irrelevant tomorrow. We have seen it for decades and now that simple rules start to take over the investment markets, the investor stands up and starts questioning [7]. “What have you been doing so long?” Markets are natural systems and need inefficiency and efficiency to function. The relationship of eating rice and driving safely [8] are naive. Even the belief that the more information the better it is, has fallen apart. It just brings us back to the 50-year old Boulding’s truth [9] that the same information could be relevant and irrelevant at different times. If A leads to B today, it is not necessary that will happen tomorrow.
It has taken the society a while to understand that the wisdom of crowds [10] worked because the madness of crowds pulled the society to the extremes, which invariably had to correct (revert). How can a system work if it does not have an internal unbalancing and balancing mechanism? The whole meaning of activity comes from inefficiency. We need irrational exuberance [11] for sanity to return. It will take a while for subjects like Socionomics [12], behavioral finance [13] and social physics [14] to look beyond emotion to a more objective quantifiable way to understand that the society cannot work without improper decision making. We need to have greed for fear. The relevance of information is rooted in its irrelevance.
Failures of Finance
A circular argument rots finance [15]. Modern finance is an extension of economics. Understanding behavior needs more than economics, it needs pure sciences to understand the mechanism that creates and diffuses bubbles. To assume that human beings are emotionally challenged because they cannot add and subtract [16] is a subjective thought process. Emotions do not create the system; they are driven by the system. The process that drives nature also drives market, this is why what started as a height experiment [17] ended up becoming a law. There is more than a fair share of mathematics in markets for us to base every irrationality on human stupidity.
Information is an assumption for modern finance. The Efficient Market Hypothesis [18] uses information to back its case for efficiency. The EMH case is weak, but as Martin Sewell [19] explains that until a flawed hypothesis is replaced by better hypothesis, criticism is of limited value. Orpheus not only challenged the information assumption in EMH based on the idea first laid out by Kenneth E. Boulding, but also highlights the body of work discussing information relevance, information irrelevance, information content since Ball and Brown [20] and illustrated how ‘Mean Reversion Framework’ (MRF) [21] can be used to re-explain the transformation of information from relevance to irrelevance, also referred to as the ‘Reversion Diversion Hypothesis’ [22].
New Architecture
According to Herbert Simon [23], the architecture of complexity [24] was intrinsically simple and hierarchal. The structure was more important than the content. There was a commonality across various types of natural systems including market systems. The whole was more than the sum, suggesting complexity generated by a definable structure.
One of the key ideas of Simon was to understand how Pareto [25] worked. How did the rich get richer? Laszlo Barabasi’s [26] work also failed to explain why sometimes there is a divergence from the ‘rich get richer’ (RGR), or why does on occasions, the first mover advantage fails to keep the incumbent ahead. How come sometimes, a non-descript late entrant, a search engine (Google) ends up becoming bigger than the first search engine (Yahoo)? Laszlo Barabasi called it the luck factor [27]. The challenge against Barabasi was brought by Keller [28], Shalizi [29], etc. This brought in a need for a new AOC. Something that could explain why sometimes the first mover could fail and the second or late entrant could succeed. In other words, it could also explain how mean reversion worked along with Praetorian divergence (exaggeration of trends).
Luckily, for us RMI [30] outperformance and excess returns across regions and assets created a constant quest. Why something so simple like the MRF delivered a better risk-weighted basket? What was the magic that created a surprising advantage so much so that we could take on the challenge?
The MRF had solved one big problem. It could explain how the rich get richer with three other cases, rich starts to lose, loser starts to become rich, loser continues to lose. It was a strange feeling when you are looking for something but end up finding something else. This is what happened to us. A simple ranking mechanism [31] answering a generational problem of 100 years. RGR is the 80-20 principle [32]. What we had found was why the 80-20 principle failed. The failure of 80-20 was the reason the rich do not always get rich, they sometimes fail.
The RGR case could be extended to the stock market, which also had four phases WW (Winners continuing to win), LL (Losers continuing to lose), WL (Winners starting to lose), LW (Losers starting to win). A closer look and some Markovian probability matrices later and the statistical evidence became clear. This is what I published in ‘Is the Smart Beta dumb?’[33]. The rules of outperformance could be inverted to build systems that underperform and drive ideas like smart inverse. [34]
So now not only we had a model that delivered superior returns, but also we had answered a big question for science. A question that could explain network thinking, explain the complexity and group behavior. MRF was the new architecture of complexity.
Well, of course, we are open to challenge not only in terms of our hypothesis but also in terms of contenders building a better allocation system that could beat the S&P500 and a host of other regional indices and cross asset baskets. But at this stage, we do not see many taking up the Granger’s basket challenge [35].
There is a thin line between courage and foolishness, but then it was only when I mustered the courage to start writing, I stumbled on to James Buchanan’s reiteration of Frank Knight view that everything, everyone, anywhere, anytime – all is open to challenge and criticism and Robert Solow’s thought that “it’s a mistake to think of economics as a Science with a capital S. There is no economic theory of everything and attempts to construct one seems to merge toward a theory of nothing”, encouraged me further. The two added on to my short list of economists, Schumpeter [36] and Boulding. And I became fearless when I thought about Schrodinger, who said, “I can see no other escape from this dilemma (lest our true who aim be lost forever) than that some of us should venture to embark on a synthesis of facts and theories, albeit with second-hand and incomplete knowledge of some of them -and at the risk of making fools of ourselves. So much for my apology.”
Data Universality
Assuming Sewell is right and till proven wrong, we have a coherent model and a framework, where does this take us? The MRF framework has been tested on multi-duration, multi-region and multi-asset classes. As I write this, Orpheus is working on a global tactical system which aspires to go cross asset on allocation. Our plan is to extend the RMI system to 3000 Indices over five years.
Strangely, what started as the Galtonian height experiment [37] was transformed into a stock market system. It was in 2010 the MRF was used on Google trends data and sentiment data [38]. The framework was universal and could look at the WW, WL, LL, LW phenomenon for any data set. This was when I was clear that MRF was universal in nature and it did not matter whether it was stock price return, sentiment data or the price of a fruit. The data innovation was universal. This is what is referred to as ‘Data Universality’.
‘While the world spends resources and time to make sense of information, it passes through stages of relevance and irrelevance. For more than half a century researchers have debated on intelligent systems that can make sense of this information. Nature is an example of an intelligent system, which selects relevant information and ignores the noise. Systems have common properties that are independent of their specific content. Data Universality is a commonality that governs a data set irrespective of its source of generation or derivation, an intelligence that defines the architecture of complexity, allowing the user to understand, anticipate and relate data intra-domain or inter-domains. Data Universality redefines anticipation (predictability) at a system level and connects industries and domain knowledge as never before. This allows the user to identify the relevant information, simplify the complex, understand the mechanism that generates uncertainty and hence manage the risk better.’
Orpheus Data Universality
So as you can see it does not matter whether it is a fruit or a stock. For the data universal system, every data set has a common group behavior.
Architecture of Data
If data had nature in it and if data indeed became the code (Neuman) [39] or we the new society was the Borge’s [40] map, the question about the architecture of data (AOD) became paramount. The structure will be more important than the inferences that come out of it because of the reasons I just mentioned. Exponentiality of data would mean dynamic, non-linear and complex systems. The challenge will still be how to map the behavior of the flock of birds, though chaotic they will have a structure and order. A single system with every component connected. Self-describing, self-interpreting, it will be intelligent and not artificial.
“Data in this world is infrastructure: a long-lived asset, general in purpose, capital intensive, and supporting multiple activities. Inference, by contrast, is short-lived, real time, trivially cheap, specific to a problem or task, continuously adapting, and perpetually self-correcting…The asymptote is where sensing, connectivity, and data merge into a single system. Every person and object of interest are connected to every other: the traffic readout on a mobile phone becomes the aggregation of all the data provided by all the mobile devices in the area reading the traffic. The world becomes self-describing and self-interpreting. At its outer limit, the digital map becomes the world itself. The world and our picture of the world are becoming the same thing: an immense, self-referential document. We are living in Borges’ map.”
Navigating a world of Digital Disruption, BCG
Architecture should have the semblance to a structure. There should be blocks, modules, components and layers. It should resemble a building or look like a bow tie [41]. How could it be stacked [42]? Though the BCG report does a good job at articulating the need for architecture, it falls short of the needed conceptualization. The architecture should allow for sharing and isolation should not be feared. Research is done in 2000 on how the web organizes itself sheds light on the fractal nature of the web. The web is a bow tie.

The bow tie is an architecture at every layer of the web, however, you may slice or dice it. There will always be isolated elements, aspiring to associate with the larger structure but failing to do so. The only AOD that can persist is the one that is natural. The weather is unpredictable but not random. Unpredictable events or systems can be described as those we are unable to forecast or only able to partially forecast, due to a lack of information. Random systems are systems in which no deterministic relationship exists [43]. This is why the researcher cannot be fooled by the millions of non-intuitive relationships [44]. The inference challenge should not be forgotten. The indistinguishable nature is the beauty of the structure.
The AOD just likes its stacked counterpart is about, collaboration, strategic thinking, ubiquitous connectivity, lower computing costs, seeking invisible patterns, software replacing hardware, the single universally accessible document, looking at data as infrastructure, quickly shared breakthroughs, self-correcting inferences, data sharing etc. AOD was built on the assumption that similar challenges and strategies applied for many businesses and that the anticipation was not just for a few days ahead but was required for years ahead. Domains were not only interconnected but interdependent.
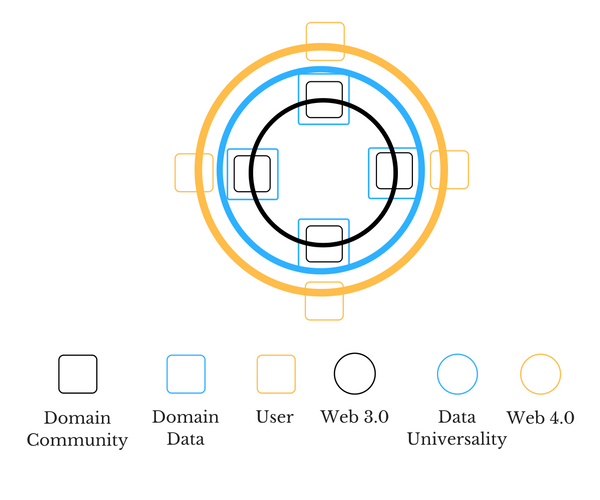
The Web 2.0 [45] is going through its data science revolution. It has community data and it starts to understand user behavior through user choices. We have crossed the stage from domain community to domain data. The AOD will be about the interaction between data from various domains. The standardization, integration, and interpretation across domains of data will be a part of the Web 3.0 [46]. This leads to data universality [47], when data commonalities are explored for individual (component) and domain (group) benefit, for inferences and to anticipate immediate and intermediate evolution. We will be the part of a thriving organism then. AOD could potentially drive Web 4.0 [48], the ultra-smart agent which caters to various user needs. Web 4.0 won’t be artificial but simply intelligent. If this proposed scenario holds, FinTech will morph into the architecture like many other components. The structure will become more important than the content.
George Taylor [50] talked about hemline index and bull markets. William Stanley Jevons [51] studied the relationship of sunspot cycles to economic cycles. Maybe in the not so distant future, we will wonder how the architecture and the mathematics of human behavior, the coexistence of rationality and irrationality of human decision-making eluded us for so long.
Bibliography
[1] Intermarket Analysis, John Murphy, 2004
[2] The Fruit Basket Paradox, Pal, 2016
[3] The Rise of Indices Is Changing the Face of Investing (S&P Dow Jones, 2016)
[4] Sarbanes-Oxley Act of 2002
[5] Did Behavioral Mutual Funds Exploit Market Inefficiencies During or after the Financial Crisis?, SSRN, Philippas, 2015
[6] Economics as a Moral Science, The American Economic Review, 1969
[7] Investors Pour Into Vanguard, Eschewing Stock Pickers, Wall Street Journal, Aug 20, 2014
[8] Navigating a world of Digital Disruption, BCG, 2015
[9] The Economics of Knowledge and the Knowledge of Economics, Kenneth E Boulding, 1966
[10] Wisdom of crowds, James Surowiecki, 2004
[11] Irrational Exuberance, Robert Shiller, 2000
[12] Socionomics, Robert Prechter, 1999
[13] Prospect Theory, Kahneman and Tversky, 1979
[14] Social Physics, Alex Pentland, 2014
[15] Arbitraging the Anomalies, Pal, 2015
[16] Can the Market Add and Subtract? Journal of Political Economy, Lamont and Thaler, 2003
[17] Regression towards mediocrity in Hereditary Stature, Galton, 1886
[18] The Adjustment of Stock Prices to New Information, Fama, Fisher, Jensen, Roll, 1969
[19] History of the Efficient Market Hypothesis, Martin Sewell, 2011
[20] An Empirical Evaluation of Accounting Income Numbers, Ball and Brown, 1968
[21] Mean Reversion Framework, Pal, 2015
[22] Reversion Diversion Hypothesis, Pal, 2016
[23] A behavioral model of rational choice, Simon, 1955
[24] Architecture of Complexity, Simon, 1962
[25] Trattato di sociologia generale, Pareto, 1916
[26] Emergence of scaling in random networks, Science, 286:509–512, Barabasi, Albert, 1999
[27] Barabási–Albert model, 1999
[28] Revisiting “Scale-Free” Networks, Keller, 2004
[29] Power-law distributions in empirical data, Clauset, Shalizi, Newman, SIAM review, 2009
[30] RMI, Serial Number 86396428; Risk Management Indexing, Serial Number 86396415
[31] Mean Reversion Framework, Pal, 2015
[32] The 80-20 principle, Richard Koch, 1997
[33] Is the Smart Beta dumb?, Pal, 2015
[34] Smart Inverse – A term coined by the author as the inverse of a Smart Beta.
[35] Reversion Diversion Hypothesis, Pal, 2015
[36] Business Cycles, Schumpeter, 1939
[37] Mean Reversion Framework, Pal, 2015
[38] The Fortune Index, Pal, 2013
[39] First Draft of a Report on the EDVAC, Neuman, 1945
[40] On Exactitude of Science, Borges, 1946
[41] The web is a bow tie, Nature, 2000
[42] Navigating a world of Digital Disruption, BCG, 2015
[43] The Strange Attractor, Pal, 2013
[44] Navigating a world of Digital Disruption, BCG, 2015
[45] Web 2.0 – describes World Wide Web websites that emphasize user-generated content,
[46] Web 3.0 – Semantic Web
[47] Data universality – Commonality of behavior in data sets across domains.
[48] Web 4.0 –Web as an ultra-smart agent
[49] FinTech – Financial Technology
[50] George Taylor – Hemline Index theory, 1926
[51] The Principles of Economics, Jevons, 1905